返回目錄 / Meeting-AI:即時轉寫、語句拆分與會議總結的 AI 會議助手
Meeting-AI Monorepo
AI 會議助手——面向會議場景的輕量級 Web 智能應用,提供即時語音轉寫、原文事件流、語句拆分、會議總結與針對性分析,並支援可配置的 GLM 模型、限流與翻譯能力,幫助團隊快速沉澱關鍵資訊與結論。
專案地址: https://github.com/7788ken/Meeting-AI-CC_GLM-CODEX
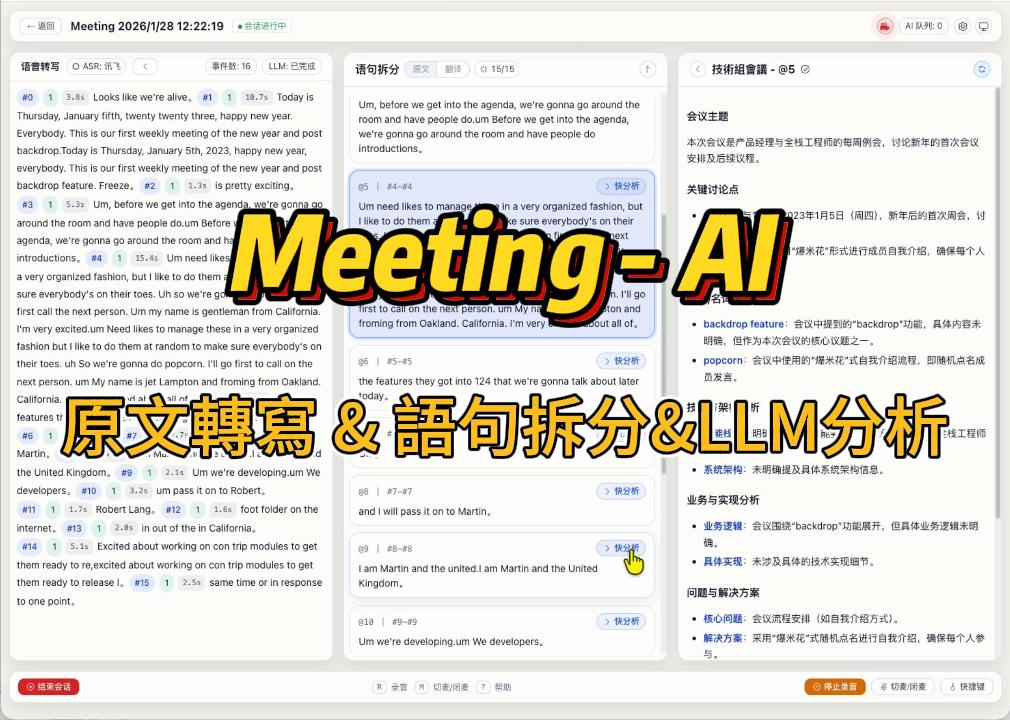

使用流程
建立會話:在首頁建立會議,填寫標題與描述。可在設定中配置 GLM 模型、提示詞與限流策略(可選)。
開始錄音:進入會議頁面點擊「開始錄音」,瀏覽器請求麥克風權限,前端透過 WebSocket
/transcript推流音訊。即時轉寫與語句拆分:GLM ASR 生成原文事件流;系統按視窗觸發語句拆分(僅做斷句與輕量標點,不改寫/翻譯)。如啟用翻譯,將對語句段生成譯文;點擊語句段可發起針對性分析。
生成會議總結:在 AI 分析面板點擊「開始分析/重新分析」,系統透過 SSE 流式生成會議總結;歷史會話可直接查看已生成的總結。
執行觀測:進入「執行中控大屏」查看 GLM 佇列、會話活動、任務日誌,並在設定面板調整配置。
你會得到的輸出
會議紀要與結論摘要(可直接分享)
決策記錄、風險清單與待辦事項
行動項與負責人建議(可手動確認)
針對性分析(點選單段內容快速聚焦)
非技術用戶小提醒
使用前提:需授權瀏覽器麥克風、保持穩定網路
錄音品質:環境越安靜、發言越清晰,轉寫與總結越準確
操作建議:錄音中不建議修改設定;需要時可「重新分析」
結果校對:重要結論建議人工確認後再對外使用
核心亮點
即時轉寫 + 事件流沉澱
原生 WebSocket
/transcript推流,支援即時 ASR 與事件級落庫(MongoDB)語句拆分支援重拆與進度提示,確保內容可追溯
可配置的語句拆分、翻譯與分析
語句拆分基於 GLM,可自訂系統提示詞與模型/Token/重試策略
語句翻譯、分析語言可開關並指定目標語言
會議總結與針對性分析支援流式輸出
維運與可觀測性
執行中控大屏展示佇列、並發、冷卻、任務日誌與會話活躍度(
/ops/stream)應用日誌與除錯錯誤可追蹤
前後端分離 + 開源可擴充
前端:Vue 3 + Vite + Pinia + Element Plus
後端:NestJS 模組化架構,分層清晰,便於二次開發
Docker Compose 一鍵部署(PostgreSQL + MongoDB + 前後端)
使用場景
企業會議管理:會議記錄、自動總結、行動項追蹤與責任人確認
技術會議/架構評審:即時彙整決策點、風險清單與後續任務分派
需求評審/產品評估:釐清需求邊界、輸出待辦與疑問清單
招聘面試:面試記錄、候選人亮點/風險摘要與面試官協同評估
面試應答訓練:針對提問即時給出回答框架與改進建議
教育培訓:課堂重點回顧、互動問答整理與課後練習建議
商務談判:談判要點萃取、對方關切點分析與策略復盤
銷售 Demo/客戶訪談:捕捉痛點與需求、生成跟進話術與行動項
專案 Standup/周會:快速彙整進展、風險阻塞與下一步任務
其他場景:透過自訂提示詞擴充到諮詢、客服、內訓等
使用場景模擬(交互示例)
面試/應試者(跨語言提問)
面試官以中英文或方言交錯提問時,系統即時轉寫並做語句拆分;若啟用翻譯,可同步顯示易讀的文字版本。
應試者可點擊某一句提問啟動「針對性分析」,快速獲得提問重點、需要覆蓋的要點與作答方向,降低誤解風險。
面試/面試官(快速理解回答)
應試者回答過快或含大量專有名詞時,系統將其拆分為可讀段落;必要時啟用翻譯,避免資訊遺漏。
面試官可點擊該段回答進行針對性分析,獲得「回答是否聚焦問題」「關鍵點是否涵蓋」「下一步可追問方向」等建議,提升評估效率。
技術架構速覽
前端:Vue 3 + Vite + Pinia + Element Plus,路由包含首頁 / 會話頁 / 執行中控大屏(
/ops/concurrency-dashboard)。後端:NestJS,模組涵蓋會話、發言、轉寫、原文事件流、語句拆分、翻譯、AI 分析、配置與維運流。
資料層:PostgreSQL(Prisma)承載會話/配置/日誌;MongoDB(Mongoose)承載發言、事件流、語句拆分與分析結果。
接入與協定:
API 預設前綴
/api,Swagger 文件/api/docsASR WebSocket
/transcript分析 SSE
/transcript-analysis/.../summary/stream與/transcript-analysis/.../analysis/stream維運 SSE
/ops/stream
執行與配置要點
GLM 接入:需配置
GLM_API_KEY,模型名稱在設定中可填寫(需與實際可用模型一致)。語言能力:ASR 支援
zh/en/yue/auto;翻譯與分析目標語言可自訂。設定安全:配置中心支援安全密碼校驗(未設定時預設放開)。
工程現狀與可優化點(基於目前程式碼)
驗證體系:後端提供 JWT 登入/註冊介面,但使用者儲存為記憶體且前端未接入;正式環境建議接入資料庫並統一鑑權(含 WebSocket/SSE)。
佇列統計口徑:目前為單實例佇列/並發統計,多實例部署需引入分散式佇列與集中指標。
權限與資料隔離:部分讀取介面對外公開,正式環境建議補齊會話歸屬校驗與存取控制。
配置治理:建議為模型與提示詞建立白名單/版本管理,避免誤配導致生成異常。
文件導覽
後端架構:
docs/wiki/backend/architecture.md後端 API:
docs/wiki/backend/api.md前端架構:
docs/wiki/frontend/architecture.md前端組件:
docs/wiki/frontend/components.md執行中控大屏:
docs/wiki/frontend/concurrency-dashboard.mdDocker 部署:
docs/wiki/deployment/docker.md
影片觀看
Meeting-ai 原文轉寫 & 語句拆分 & 針對性分析:https://youtu.be/yVVgQmg2gaY
Meeting-ai 轉寫定位 & 針對性分析 & 總結分析:https://youtu.be/yVVgQmg2gaY
Meeting-ai 語句重拆 展示:https://youtu.be/uTm4E_a6cSU
[推薦]Meeting-ai ASR 轉寫 & 語句拆分 & 自動翻譯:https://youtu.be/7iniVMdiPh4