返回目錄 / 關於ChatGPT企業應該知道的10個要點
要擁抱爆紅的ChatGPT技術,企業考量和個人使用截然不同,我們整理了企業上手ChatGPT技術前,得先知道的十件事
今年3月1日,OpenAI正式跨入企業應用市場,釋出了ChatGPT背後GPT-3.5版模型的付費API服務,也跨進了更多企業對話式應用情境,從搜尋、問答、客服、導覽到語音操控等。
不到2周,新一代GPT-4模型問世,不只文字,還能輸入圖片,帶來了生成式AI更多種應用的可能,不只是回答問題,還可以解釋圖片、看圖答題,或是分析圖表趨勢,甚至,只要輸入一張手繪的網站設計草圖,GPT-4就能自動生成對應網頁的程式碼。不只國外企業,臺灣金融業、製造業、政府和教育機構都躍躍欲試,想要開始採用ChatGPT背後的超大語言模型技術。
不過,企業擁抱GPT的考量,和個人使用截然不同,我們整理了10個企業擁抱ChatGPT技術要先知道的10個QA。
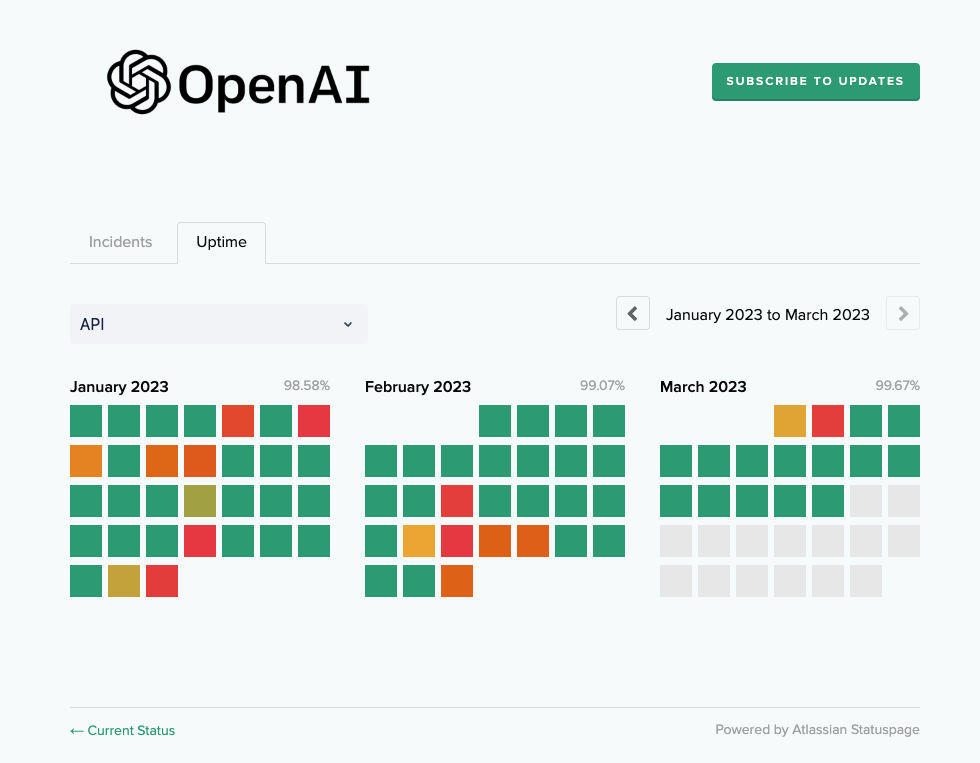
OpenAI的付費API沒有提出服務可用性的保證,根據其服務狀態儀表板來看,API可用性約98~99%,每個月會中斷30~40分鐘。這是企業採用前要留意的事。
Q:GPT、ChatGPT、OpenAI和Azure OpenAI有何不同?
A 這是上手ChatGPT技術前要先釐清的四個名詞,ChatGPT應用是爆紅的AI對話服務,背後所用的生成式AI模型就是GPT模型的3.5版本,而開發出ChatGPT應用的公司就是OpenAI,他們也在3月1日釋出了OpenAI的API服務,其中就包括了ChatGPT模型的API。而微軟則是將OpenAI的技術部署到Azure上來提供,也就是Azure OpenAI服務。
Q:OpenAI和Azure提供的ChatGPT技術API有什麼不同?
A 在技術上,凡是OpenAI公司提供API功能或模型,微軟承諾會盡快跟進在自家Azure OpenAI服務上提供。兩者主要不同是,OpenAI公司的API傾向於研發、研究使用為主,而微軟則比照原本Azure公雲的服務等級,提供了更多資安強化(例如VLAN傳輸)、服務可用性承諾(例如99.9%的的SLA)、企業合規要求、顧客資料保護承諾、隱私機制、AI倫理機制等。另外,企業則可自助申請快速啟用OpenAI的付費API服務,但Azure OpenAI目前則採審查申請制,需等待一段時間審查才能開通。
Q:企業可以使用哪些OpenAI生成式模型?
A OpenAI目前可以提供最新多模態的GPT-4(限定測試版)以及ChatGPT所用的GPT-3.5版模型,以及GPT-3模型,另外還提供了圖片生成式模型DALL·E (測試版)、語音轉文字的Whisper模型(測試版)、程式碼生成模型Codex(限定測試版)、過濾敏感資料的微調模型Moderation,還有一個適合用於企業內部運用的Embeddings模型API。不過,這些模型都是公版的基礎模型(base-model),企業若希望模型能更佳客製化,需要進行模型微調(Finetune)或是輸入提示(Prompt)來引導。
Q:提示和微調有什麼不同?
A ChatGPT可以輸入提示文字(prompt)來引導ChatGPT產生的內容,越來越符合使用者預期的需求,同樣也可以用於OpenAI的API,甚至出現了「AI提示工程師」(Prompt Engineer)或者更詩意的「AI詠唱者」說法,只要提問的問題問得好,就越能得到更貼切的答案。
但是,輸入提示給基礎模型,不會改變基礎模型本身的權重。因此,每一次都要重新輸入提示文字才能得到想要的答案。若要建立客製化的模型,企業得改用微調(Finetune)的方式,輸入一批自己的資料,來調教OpenAI提供的基礎模型,產生自己的客製化模型。不過,目前OpenAI還沒有開放GPT-3.5和GPT-4的微調,只能透過提示工程來進行客製化。另外,微調也不是重新訓練整套GPT模型,而是針對使用者提供的少量數據來改變部分參數的權重(或者可以說是加上一個屬性模型),讓模型輸出的結果更符合使用者的期待,因此,微調模型不需要龐大訓練資料,也不需要像重新訓練那樣費時及龐大成本。
Q:為何要計算Token? 一次最多上傳多少字?
A 當輸入一段文字到API後,OpenAI會抽取這段文字中的詞或概念(類似斷詞),將文字轉換成一個個Token。以中文字來說,平均一千個中文字約有600~700個Token不等,但還要看文字內容而定。OpneAI的API上傳限制就是按照Token數量來計算,例如 GPT-3.5模型的上限是4K個Token,而GPT-4則增加了四倍,最大到32K個(不過,目前只開放特定用戶)。Token也是OpenAI API的計價單位,以對話用的gpt-3.5-turbo的API來說,每千個Token要價0.002美元,而最新的GPT-4的32K引擎版本則每千個Token要價0.12美元,後者貴了60倍。
Q:什麼是Embeddings模型?有什麼用途?
A 不同於GPT-4或GPT-3.5是生成媲美人話的文字來回覆使用者,Embeddings模型是將輸入的文字轉換成一個浮點數值的嵌入向量(Embeddings Vector),當兩段文字的向量距離越近(可透過向量計算得到),就代表了這兩段文字的關聯性越高。可以用於搜尋(比對一段話在一篇文章中的位置,或從一批文章找出最相關者)、分類用途(將相關性高的文章分成同一群)、尋找關鍵字(找出中一篇文章最相關的幾個關鍵詞)等。摩根士丹利財管公司就是利用Embeddings功能來搜尋和整理龐大知識資產。
Q:企業能不能下載模型到本地端部署?
A 不能,不論是OpenAI或Azure都沒有提供GPT-3.5或GPT-4的本地端部署,企業只能將資料上傳到雲端API。透過微調產生的客製化模型,也只能儲存在雲端,透過API呼叫來使用,無法下載部署。
Q:OpenAI將資料儲存在哪?
A 目前全都儲存在Azure美國機房,微軟的Azure OpenAI服務也是。所以,對臺灣企業而言,等於是境外服務。
Q:企業上傳的資料會不會變成訓練資料?
A 企業上傳到OpenAI的資料可分為兩類,一類是每次輸入的提示文字或問題,另一類是用來微調模型的數據。OpenAI承諾從3月1日後不會用這些提示文字資料來訓練(代表之前會),不過,企業可選擇願意授權給他們用於訓練。對於第二類,OpenAI保證只會用於顧客自己模型的微調,不做他用。微軟則比照Azure政策,不會私自使用顧客上傳的資料也不會賣給第三方。不過,不論是OpenAI或微軟,對於輸入的第一類提示文字則會保留30天,以供敏感資料的真人審查之用。
Q:為何需要真人審查?企業能不能拒絕?
A GPT-4目前只能過濾8成敏感內容(不當指令攔截可超過95%但並非100%),而gpt-3.5-turbo甚至不到6成,因此,OpenAI在特定情況下會由少數獲得授權的真人來審查有疑慮的內容,微軟Auzre OpenAI服務也是如此,不過,微軟也提供企業可以專案申請免除真人審查。
從微軟在Azure的說明文件中,可以看到,微軟的OpenAI服務運作流程如下,可以分為四種使用行為以及對象的四大類資料,第一類是企業所建立的微調訓練任務資訊(這是用來客製化模型用的程式碼或後設資料,主要用於訓練一個客製化模型),直接上傳的訓練用檔案(通常是企業上傳的訓練資料集),另外還有第三類是透過回答、搜尋或嵌入向量等API呼叫輸入的資料(通常是企業透過API呼叫時所上傳的參數內容),最後一類則是生成的結果。第一類資料會直接放入到訓練基礎架構中,而第二類訓練資料集則會集中到訓練資料儲存處,再提供給訓練基礎架構來使用,最後微調訓練出一個客製化的模型,Azure會將這個客製化模型部署到預測/推論基礎架構來部署。當企業透過API上傳的參數,例如提問,提示文字等,則會用客製化的模型來推論,來產生出最後一類「生成結果」。每次當模型完成推論後,也會同時將所有透過API輸入的資料(第三類資料和輸入參數)和生成的結果集中到一個顧客資料儲存庫中,保留30天,以供日後真人檢查之需。另一方面,所有生成結果也會非同步送到一個預警系統,一但發現有不雅或不當內容,就會發送警告給特定獲得授權的真人稽核人員,針對企業所上傳的資料和生成結果來審查。
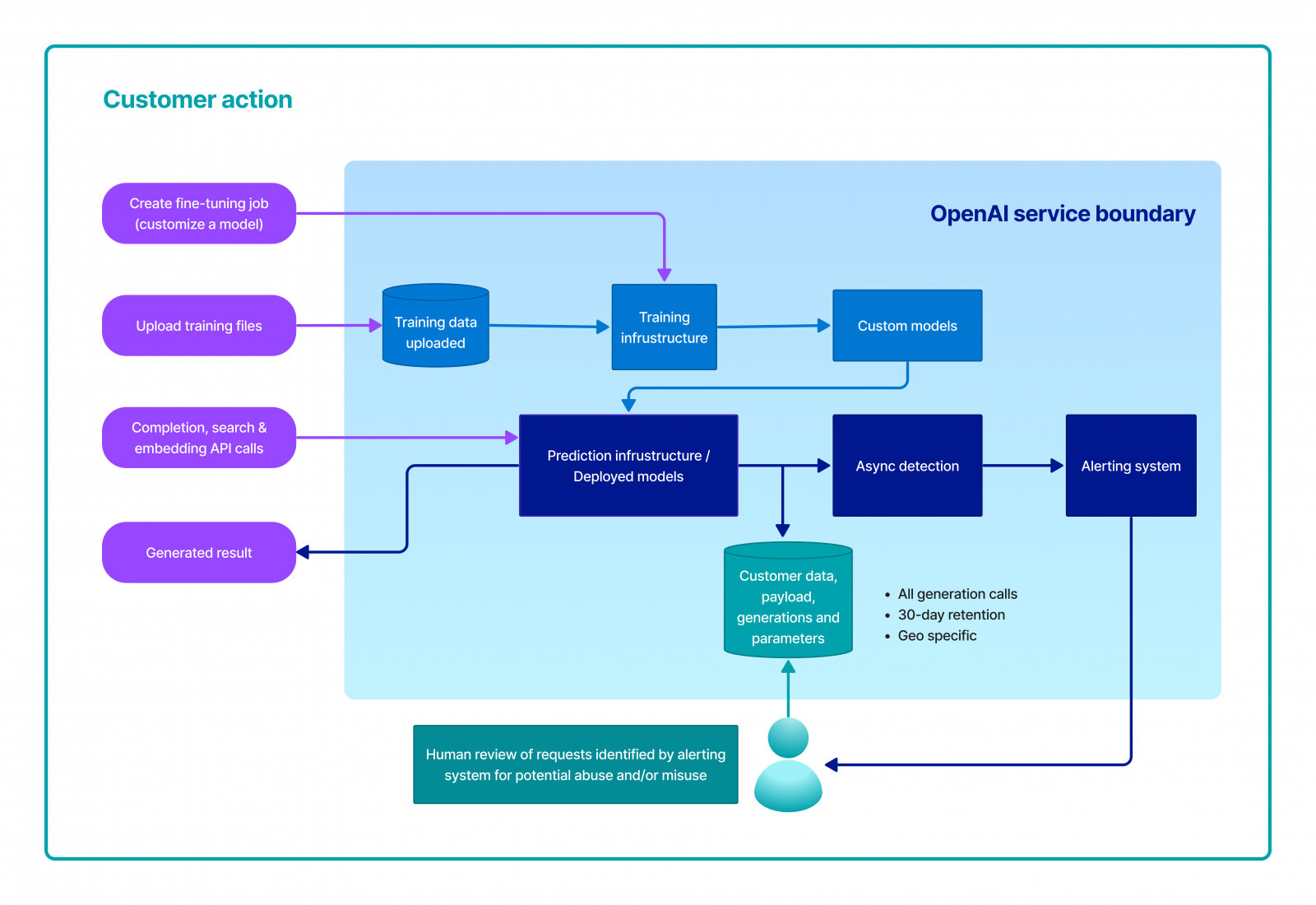
不論是OpenAI或微軟,對於企業輸入的提示文字會保留30天,以供敏感資料的真人審查之用。不過,微軟開放企業專案申請免除真人審查。圖片來源/微軟
文章來源:https://www.ithome.com.tw/news/155973